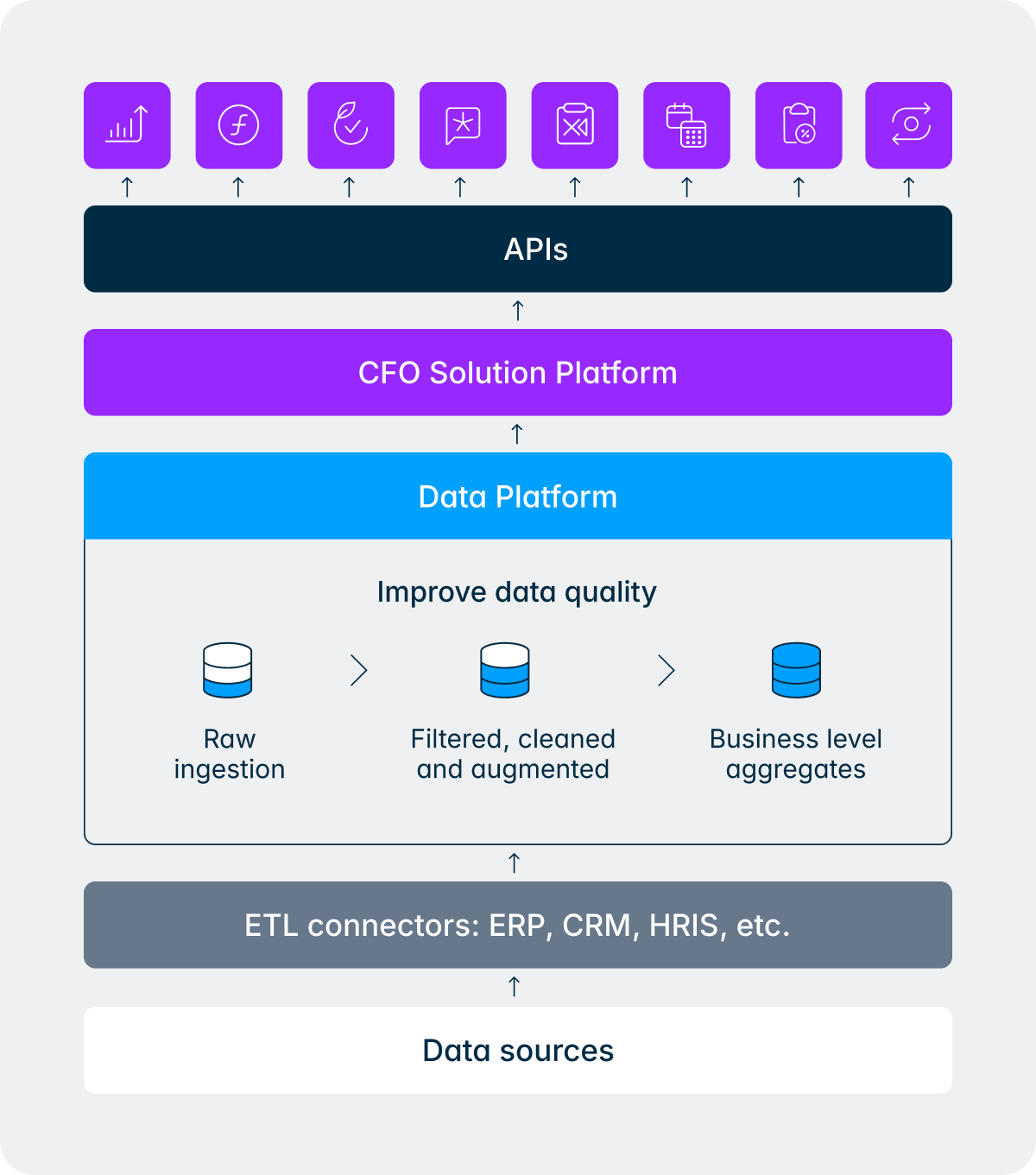
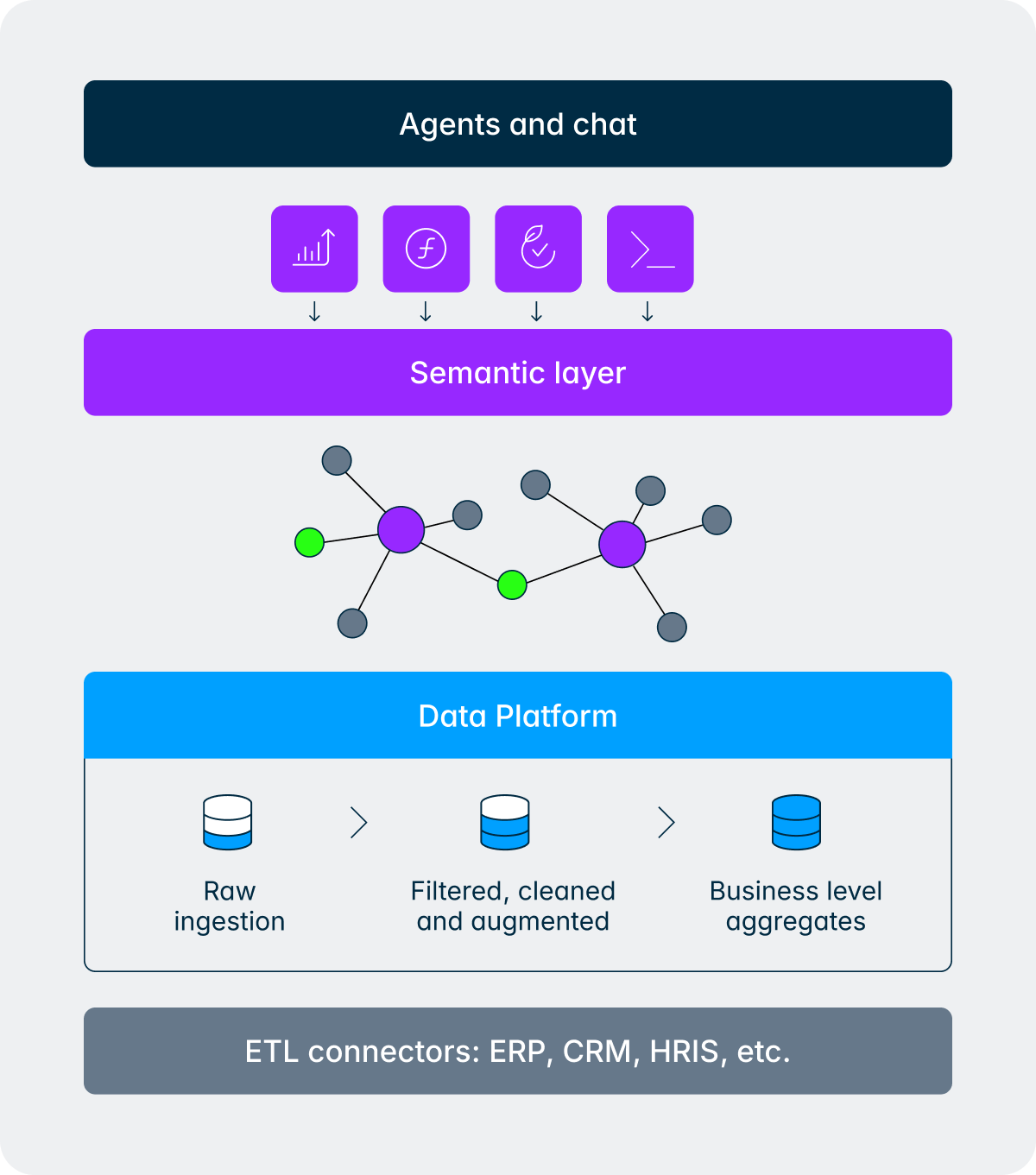
Take a question a CFO might ask the night before a board meeting:
“How did our UK revenue grow last year compared to Germany, and what does sales headcount and new customer count look like in those regions?”
That single question touches accounting data (revenue), operational data (customer data from the CRM), headcount information (from the HRIS), two entities, a year-on-year comparison, and a regional view. Here is how the agent and the semantic layer handle it together:
- The user asks the question in natural language.
- The agent reasons about what is being asked: which financial concepts, which operational concepts, which dimensions, which time period.
- The agent sends one or more data requests to the semantic layer.
- The semantic layer traverses the knowledge graph to identify the relevant tables, joins, and dimensions across the financial, HR, and operational data sets.
- Dimension resolution translates business terms into specific identifiers (UK and Germany legal entities, correct fiscal year, revenue accounts, headcount category, customer metric definition).
- The semantic layer fetches the data, executes the queries against the gold layer, and returns structured results.
- The agent uses those results to answer the question, with a chart and a narrative, and the Intelligence Core captures the trace so the user can see exactly how the answer was produced.
What previously took a finance business partner half a day, with a BI ticket and a follow-up reconciliation, now takes seconds. The agent is not guessing. It is asking your data warehouse the right questions, in your own business language.
PhD -level intelligence, but day 1 on the job
There is a useful mental model for thinking about LLM-powered agents: imagine you have just hired someone with PhD-level intelligence, extraordinary reasoning ability, and deep knowledge across a remarkable breadth of domains, but it is their first day on the job. They know nothing about your specific consolidation structure, your chart of accounts, your intercompany agreements, your reporting deadlines, or the dozens of small conventions your finance and tax teams have built up over years. Raw intelligence is necessary, but on its own it is nowhere near sufficient.
The Intelligence Core together with the Data Platform are designed to close this gap. When an agent operates within the platform, it does not rely solely on the general knowledge baked into the LLM. Instead, the Intelligence Core provides the agent with structured access to the context it needs: your consolidation rules, your group structure, your mapping logic, your historical data, and the metadata that describes how your specific environment is configured. The agent reasons with the full capability of the underlying model, but it reasons over your data, grounded in your reality rather than in generalities.
A new hire gets better over time because they accumulate context that is specific to your organization. They learn that a particular intercompany elimination requires special treatment, that a specific cost center follows a non-standard allocation, or that the group reporting package has a nuance around currency translation for a recently acquired subsidiary.
When our agents need additional information to complete a task, they will ask you questions, such as “when does your reporting period start”. They also ask if you’d like them to ‘remember’ a specific fact or piece of information for future use. And where is that information stored? The Data Platform, sitting alongside the rest of your data. Over time, your institutional knowledge is built. The more your team works with our agents, the more competent those agents become at the specifics of your business. That is by design.
Is my data secure?
Cyber security is a fast-moving discipline, and the arrival of capable LLMs has made it move faster still. The CFO Solution Platform was built with that reality in mind, with multiple layers of defense, modern detection and response, and a security posture that is monitored continuously.
The CFO Solution Platform is deployed into five geographic regions, each fully isolated. When a new customer onboards, they choose where their tenant lives, geographically.. Each region is divided into what we refer to as tenant pools: groups of customers (tenants) that are isolated from each other. Within a tenant pool, each individual tenant is strongly isolated from every other tenant, making it impossible for one tenant to see another tenant’s data. Data is encrypted in transit and at rest. We call this our strong isolation model. Achieving this level of separation required a disproportionate investment in our core platform infrastructure, and we believe it is one of the most important investments we have made.
The Data Platform inherits this strong isolation model. Your raw data, your cleansed data, your gold layer, your knowledge graph, and the agent memory all sit inside your tenant, encrypted, isolated, and protected.
A couple of Data Platform points worth calling out:
- Permissioned by default: An agent will only be able to see the data its user is permitted to see. Users cannot use agents to elevate their own access. Role-based access from your existing identity provider will flow through the Data Platform and the semantic layer.
- Data minimization at the LLM boundary: When an agent uses an LLM to reason, we only pass across the data that is absolutely needed. We use LLMs hosted in the same region as your tenant, and under our enterprise agreements with model providers, prompts and responses are neither retained nor used for model training.
To keep ourselves honest, and ensure we’ve not missed something, we also invest time and effort in obtaining the most relevant certifications and meeting the highest compliance standards. These include SOC 1, SOC 2, ISO 27001, ISO 27017, and ISO 27018. We are also working to complete ISO 42001 (the international standard for AI management systems) and BSI C5 (the German government’s benchmark for cloud security), both of which we expect to achieve by summer 2026. Beyond certifications, we are actively aligning to the EU AI Act, NIS2, and the upcoming Cyber Resilience Act. And for our customers operating in DORA-regulated environments, our platform is designed to support their operational resilience requirements. Security is one of the load-bearing decisions in how the Data Platform is built.
Want to see Lucanet's intelligent CFO Solution Platform in action?
Join our webinar to get an exclusive preview of the next generation of workflow agents coming to the CFO Solution Platform.
Register now