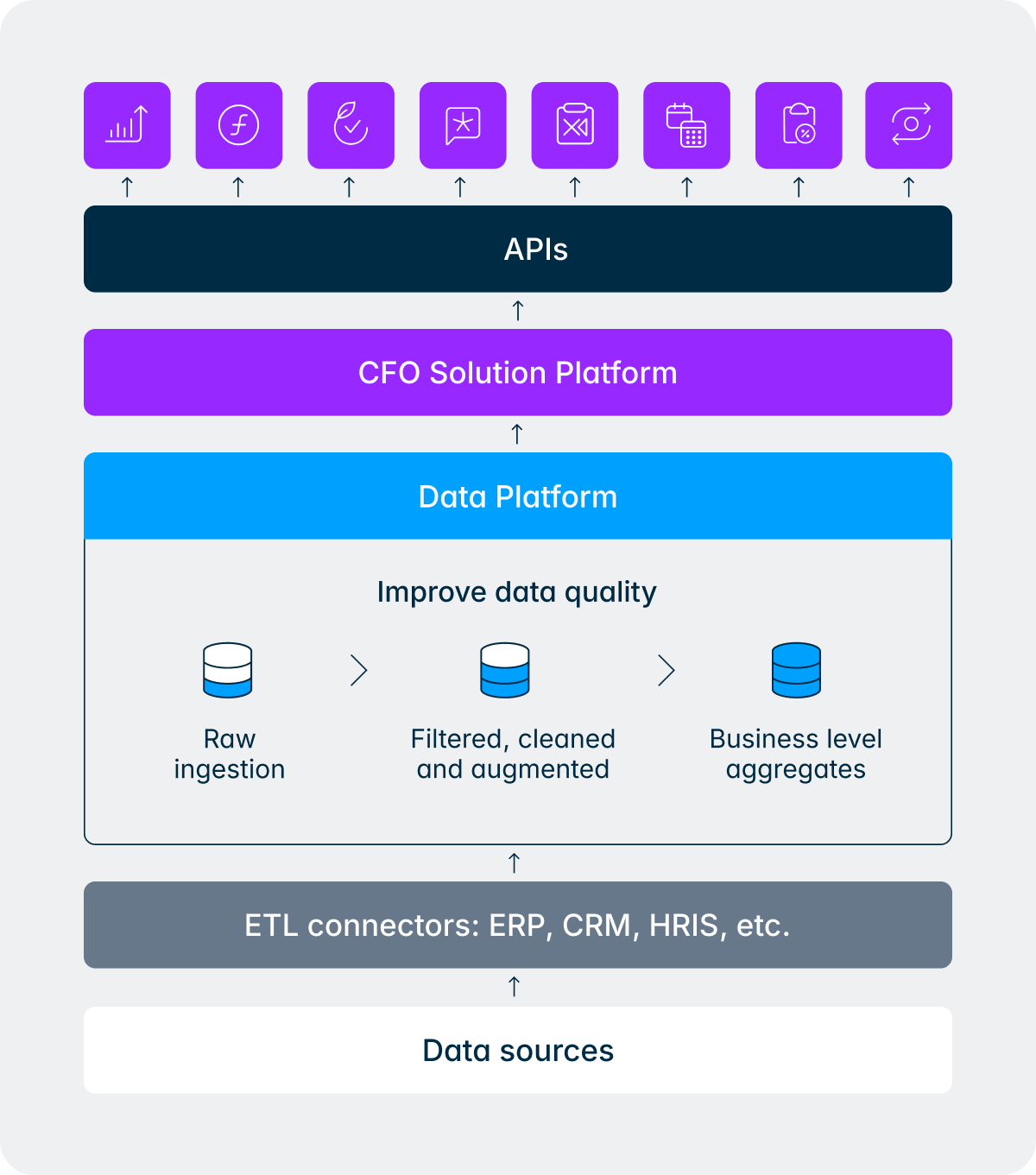
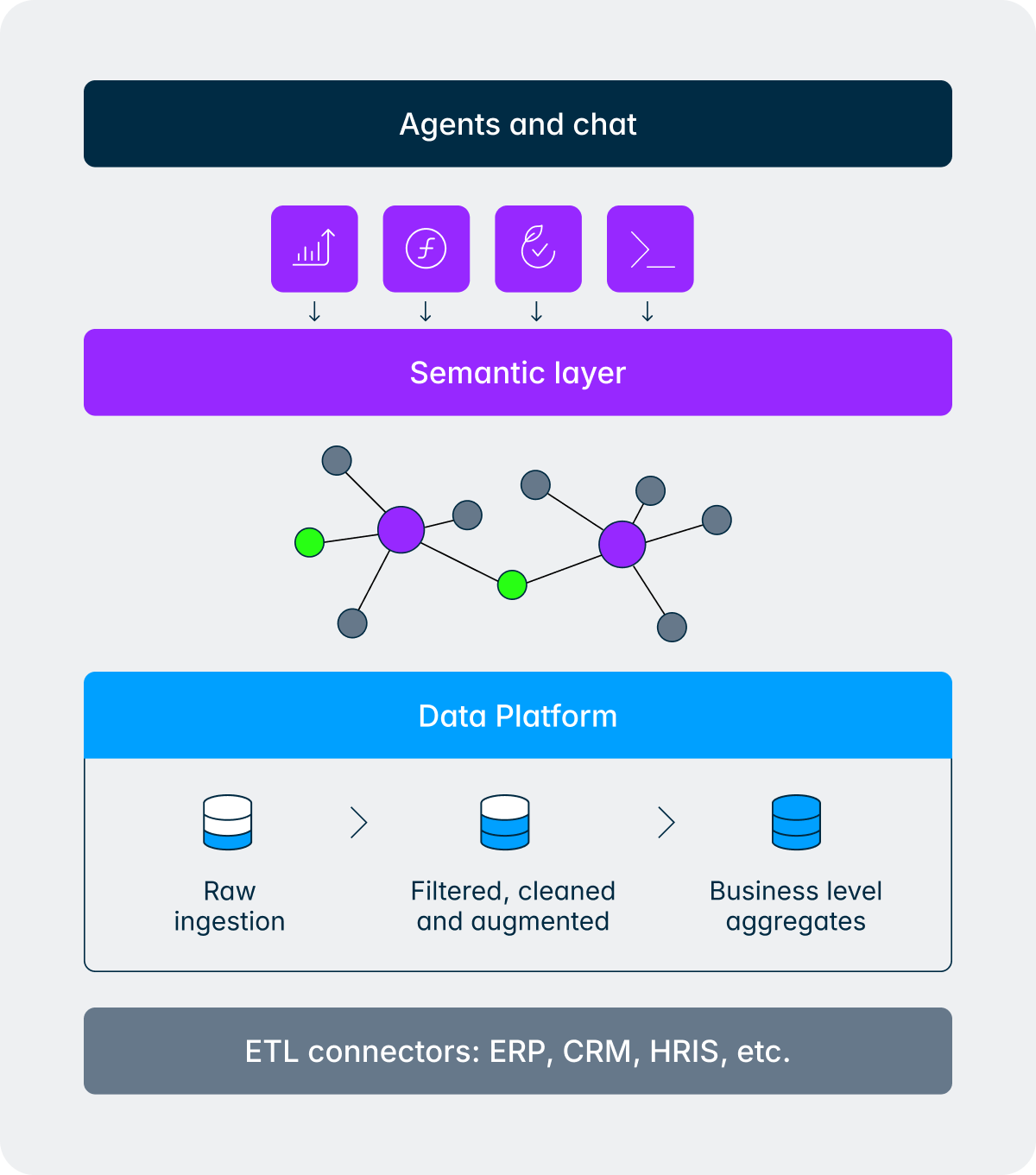
Nehmen wir eine Frage, die ein CFO am Abend vor einem Board-Meeting stellen könnte:
„Wie ist unser Umsatz im Vereinigten Königreich im letzten Jahr im Vergleich zu Deutschland gewachsen und wie sehen der Personalbestand im Vertrieb und die Anzahl der Neukunden in diesen Regionen aus?“
Diese eine Frage berührt Buchhaltungsdaten (Umsatz), operative Daten (Kundendaten aus dem CRM), Personalbestandsinformationen (aus dem HRIS), zwei Unternehmen, einen Jahresvergleich und eine regionale Ansicht. So gehen der Agent und die semantische Ebene damit um:
- Der User stellt die Frage in natürlicher Sprache.
- Der Agent schlussfolgert darüber, was gefragt wird: welche Finanzkonzepte, welche operativen Konzepte, welche Dimensionen, welcher Zeitraum.
- Der Agent sendet eine Datenanfrage oder mehrere an die semantische Ebene.
- Die semantische Ebene durchläuft den Wissensgraphen, um die betreffenden Tabellen, Joins und Dimensionen in den finanziellen, Personal- und operativen Datensätzen zu identifizieren.
- Die Dimensionsauflösung übersetzt Geschäftsbegriffe in spezifische Kennungen (britische und deutsche Unternehmen, korrektes Geschäftsjahr, Umsatzkonten, Personalbestandskategorie, Kundenmetriken-Definition).
- Die semantische Ebene ruft die Daten ab, führt die Abfragen gegen die Gold-Ebene aus und gibt strukturierte Ergebnisse zurück.
- Der Agent verwendet diese Ergebnisse, um die Frage mit einem Diagramm und einer Erläuterung zu beantworten. Der Intelligence Core zeichnet den Ablauf auf, sodass der User genau sehen kann, wie die Antwort zustande kam.
Was früher einen Finance-Business-Partner einen halben Tag kostete – mit einem BI-Ticket und einer Folgeabstimmung – dauert jetzt Sekunden Der Agent rät nicht. Er stellt Ihrem Data Warehouse die richtigen Fragen, in Ihrer eigenen Geschäftssprache.
Intelligenz auf Doktorandenebene, ab dem 1. Arbeitstag
Es gibt ein nützliches Denkmodell über LLM-gestützte Agenten: Stellen Sie sich vor, Sie hätten gerade jemanden eingestellt, der promoviert ist, über außergewöhnliche Schlussfolgerungsfähigkeiten und fundiertes Wissen in einer bemerkenswerten Bandbreite von Bereichen verfügt, aber es ist der erste Arbeitstag. Die entsprechende Person weiß nichts über Ihre spezifische Konsolidierungsstruktur, Ihren Kontenplan, Ihre Intercompany-Vereinbarungen, Ihre Reporting-Fristen oder die Dutzenden kleiner Konventionen, die Ihre Finance- und Tax-Teams über Jahre aufgebaut haben. Rohe Intelligenz ist notwendig, reicht aber bei weitem nicht aus.
Der Intelligence Core zusammen mit der Data Platform sind beide darauf ausgelegt, diese Lücke zu schließen. Wenn ein Agent innerhalb der Plattform operiert, stützt er sich nicht ausschließlich auf das im LLM verankerte allgemeine Wissen. Stattdessen liefert der Intelligence Core dem Agenten einen strukturierten Zugriff auf den Kontext, den er benötigt: Ihre Konsolidierungsregeln, Ihre Konzernstruktur, Ihre Mapping-Logik, Ihre historischen Daten und die Metadaten, die beschreiben, wie Ihre spezifische Umgebung konfiguriert ist. Der Agent schlussfolgert mit der kompletten Fähigkeit des zugrunde liegenden Modells, aber er argumentiert auf der Grundlage Ihrer Daten, basierend auf Ihrer Realität und nicht auf Verallgemeinerungen.
Neu eingestellte Personen werden mit der Zeit immer besser, weil sie sich Ihren unternehmensspezifischen Kontext aneignen. Sie lernen, dass eine bestimmte Intercompany-Eliminierung eine besondere Behandlung erfordert, dass eine spezifische Kostenstelle einer nicht Standard-Allokation folgt oder dass das Konzern-Reporting-Paket eine Besonderheit bei der Währungsumrechnung für eine kürzlich erworbene Tochtergesellschaft aufweist.
Wenn unsere Agenten zusätzliche Informationen benötigen, um eine Aufgabe zu abzuschließen, stellen sie Ihnen Fragen, wie beispielsweise: „Wann beginnt Ihr Berichtszeitraum?“ Sie fragen auch, ob sie sich eine bestimmte Tatsache oder Information für die spätere Verwendung „merken“ sollen. Und wo werden diese Informationen gespeichert? In der Data Platform, die sich neben Ihren übrigen Daten befindet. Im Laufe der Zeit wird Ihr institutionelles Wissen aufgebaut. Je mehr Ihr Team mit unseren Agenten zusammenarbeitet, desto kompetenter werden diese Agenten in Bezug auf die Besonderheiten Ihres Geschäfts. Das ist beabsichtigt.
Sind meine Daten sicher?
Die Cybersicherheit ist ein sich schnell entwickelndes Fachgebiet und das Aufkommen leistungsfähiger LLMs hat diese Entwicklung noch beschleunigt. Die CFO Solution Platform wurde genau für diesen Zweck entwickelt, mit mehreren Verteidigungsebenen, moderner Erkennung und Reaktion und einem Sicherheitsstatus, der kontinuierlich überwacht wird.
Die CFO Solution Platform wird in fünf geographischen Regionen bereitgestellt, die alle vollständig isoliert sind. Wenn sich ein neuer Kunde anmeldet, wählt er den geografischen Standort seines Tenants aus. Jede Region ist in sogenannte Tenant-Pools unterteilt: Gruppen von Kunden (Tenants), die voneinander isoliert sind. Innerhalb eines Tenant-Pools ist jeder einzelne Tenant streng von allen anderen Tenants isoliert, daher ist es für einen Tenant unmöglich, die Daten eines anderen Tenants zu sehen. Die Daten werden bei der Übertragung und im Ruhezustand verschlüsselt. Wir nennen das unser strenges Isolationsmodell. Um diesen Grad an Trennung zu erreichen, war eine unverhältnismäßig hohe Investition in unsere Kernplattforminfrastruktur erforderlich und wir sind der Meinung, dass dies eine der wichtigsten Investitionen ist, die wir vorgenommen haben.
Die Data Platform übernimmt dieses strenge Isolationsmodell. Ihre Rohdaten, Ihre bereinigten Daten, Ihre Goldebene, Ihr Wissensgraph und der Agentenspeicher befinden sich alle in Ihrem Tenant, sind verschlüsselt, isoliert und geschützt.
Ein paar Punkte zur Data Platform, die erwähnenswert sind:
- Standardmäßig berechtigt: Ein Agent kann nur die Daten sehen, die sein Anwender sehen darf. Anwender können keine Agenten nutzen, um ihre eigenen Zugriffsberechtigungen zu erweitern. Der rollenbasierte Zugriff von Ihrem bestehenden Identitätsanbieter aus erfolgt über die Data Platform und die semantische Ebene.
- Datenminimierung an der LLM-Grenze: Wenn ein Agent ein LLM für Schlussfolgerungen verwendet, geben wir nur die absolut benötigten Daten weiter. Wir nutzen LLMs, die in derselben Region wie Ihr Tenant gehostet werden, und gemäß unseren Enterprise-Vereinbarungen mit Modellanbietern werden Prompts und Antworten weder gespeichert noch für das Modelltraining verwendet.
Um uns selbst treu zu bleiben und sicherzustellen, dass wir nichts übersehen haben, investieren wir auch Zeit und Mühe, um die relevantesten Zertifizierungen zu erhalten und die höchsten Compliance-Standards zu erfüllen. Dazu gehören SOC 1, SOC 2, ISO 27001, ISO 27017 und ISO 27018. Wir arbeiten außerdem daran, ISO 42001 (den internationalen Standard für KI-Managementsysteme) und BSI C5 (den Referenzwert der deutschen Regierung für Cloud-Sicherheit) abzuschließen, die wir voraussichtlich bis Sommer 2026 erreichen werden. Über Zertifizierungen hinaus richten wir uns aktiv auf die EU-KI-Verordnung, NIS2 und den bevorstehenden Cyber Resilience Act aus. Und für unsere Kunden, die in DORA-regulierten Umgebungen tätig sind, ist unsere Plattform darauf ausgelegt, ihre Anforderungen an die operative Resilienz zu unterstützen. Sicherheit ist eine der entscheidenden Aspekte bei der Entwicklung der Data Platform.
Möchten Sie die intelligente CFO Solution Platform von Lucanet in Aktion erleben?
Nehmen Sie an unserem Webinar teil und erhalten Sie eine exklusive Vorschau auf die nächste Generation von Workflow-Agenten innerhalb der CFO Solution Platform.
Jetzt registrieren