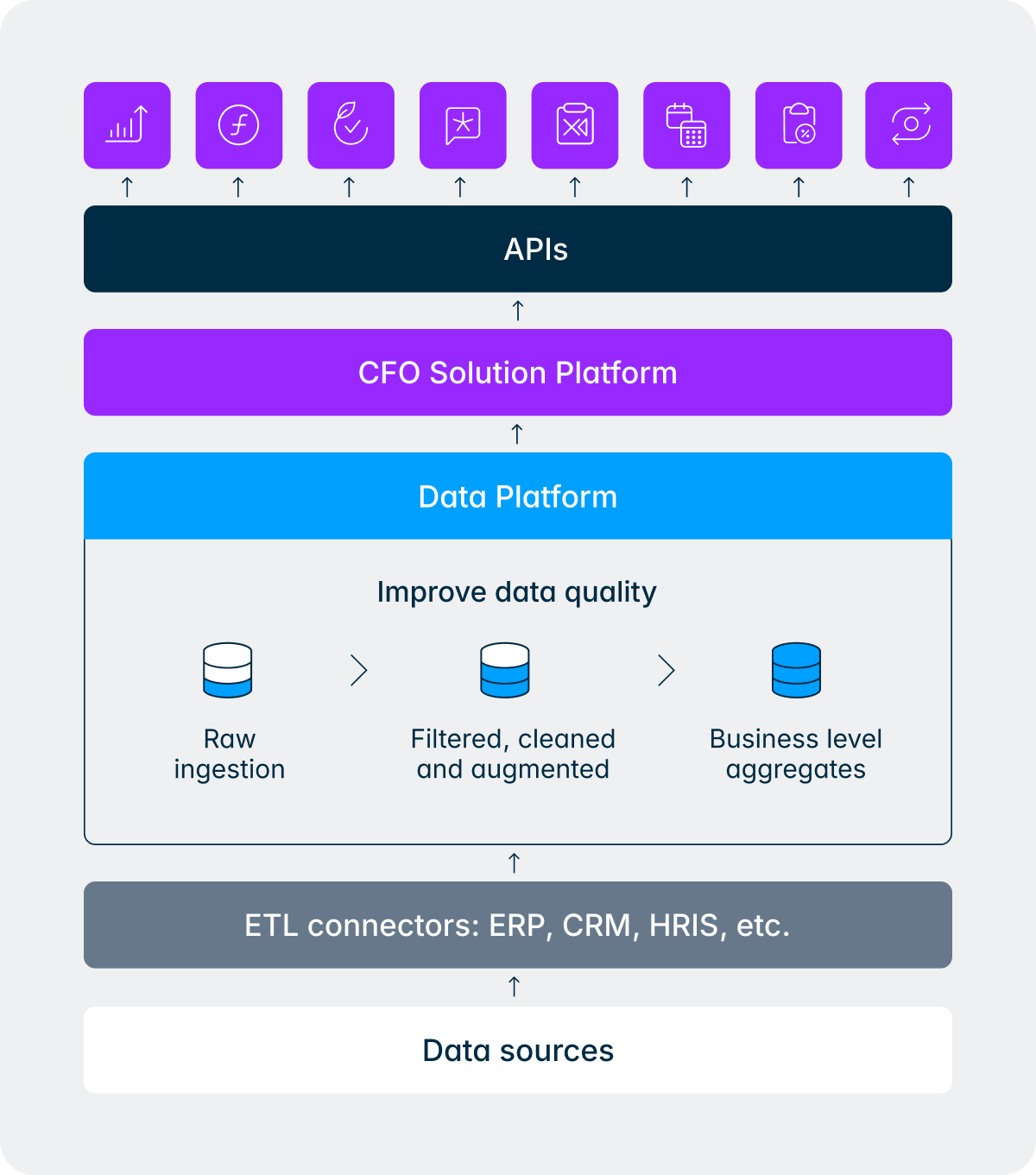
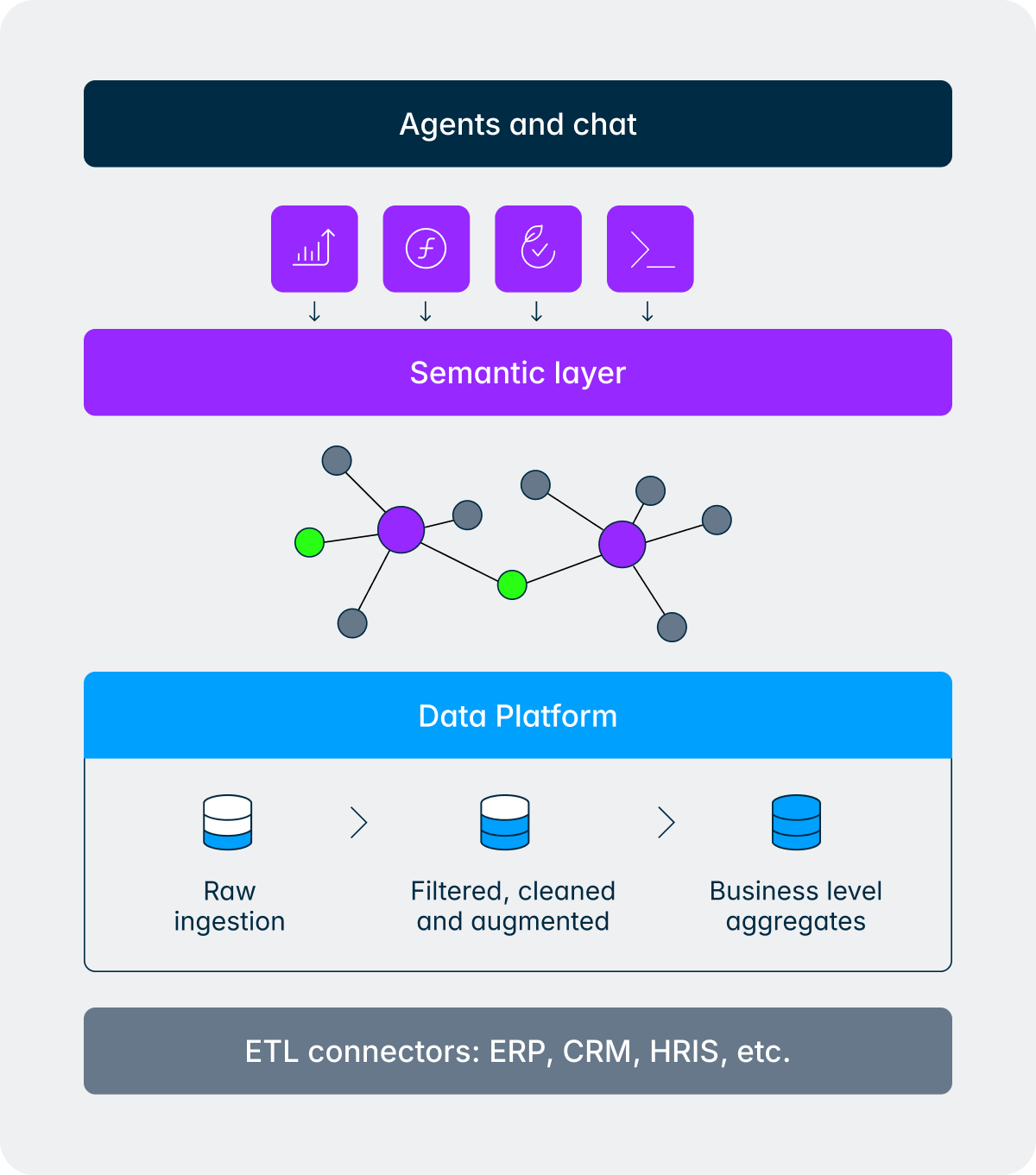
Prenez une question qu’un CFO pourrait se poser la veille d’une réunion du conseil d’administration :
« Comment notre chiffre d’affaires au Royaume-Uni a-t-il évolué l’an dernier par rapport à l’Allemagne, et qu’en est-il des effectifs commerciaux et du nombre de nouveaux clients dans ces régions ? »
Cette seule question concerne les données comptables (chiffre d’affaires), les données opérationnelles (données clients du CRM), les informations sur les effectifs (provenant du SIRH), deux entités, une comparaison annuelle et une vue régionale. Voici comment l’agent et la couche sémantique gèrent cela ensemble :
- L’utilisateur pose la question en langage naturel.
- L’agent raisonne sur la requête : quels concepts financiers, quels concepts opérationnels, quelles dimensions et quelle période sont concernés.
- L’agent envoie une ou plusieurs requêtes de données à la couche sémantique.
- La couche sémantique parcourt le graphe de connaissances pour identifier les tableaux, les liens et les dimensions pertinentes dans les ensembles de données financières, RH et opérationnelles.
- La résolution des dimensions traduit les termes métier en identifiants concrets (entités juridiques du Royaume-Uni et de l’Allemagne, bon exercice comptable, comptes de revenus, catégorie d’effectifs, définition des métriques clients).
- La couche sémantique récupère les données, exécute les requêtes sur la couche or, et renvoie des résultats structurés.
- L’agent utilise ces résultats pour répondre à la question à l’aide d’un graphique et d’un récit, et l’Intelligence Core enregistre le cheminement emprunté afin que l’utilisateur puisse voir exactement comment la réponse a été produite.
Ce qui prenait auparavant une demi-journée à un business partner, avec un ticket BI et un rapprochement ultérieur, ne prend plus que quelques secondes. L’agent ne devine rien. Il interroge votre entrepôt de données avec les bonnes questions, dans votre propre langage métier.
L’intelligence d’un doctorant, mais l’expérience d’un débutant
Pour vous représenter les agents alimentés par des LLM, une analogie est parlante : imaginez recruter un profil avec une intelligence de niveau doctorat, une capacité de raisonnement hors norme et des connaissances couvrant de nombreux domaines, mais que c'est son tout premier jour dans l’entreprise. Cette personne ne sait rien de votre structure de consolidation spécifique, de votre plan comptable, de vos accords intra-groupes, de vos délais de reporting, ni des dizaines de petites conventions que vos équipes financières et fiscales ont mises en place au fil des ans. L’intelligence brute est nécessaire, mais à elle seule, elle est loin d’être suffisante.
L’Intelligence Core et la plateforme de données sont conçus pour combler cette lacune. Lorsqu’un agent opère au sein de la plateforme, il ne s’appuie pas uniquement sur les connaissances générales intégrées dans le LLM. Au contraire, l’Intelligence Core fournit à l’agent un accès structuré au contexte dont il a besoin : vos règles de consolidation, votre structure de groupe, votre logique de cartographie, vos données historiques, et les métadonnées qui décrivent comment votre environnement spécifique est configuré. L’agent raisonne avec toute la capacité du modèle sous-jacent, mais il raisonne sur vos données, en s’appuyant sur votre réalité plutôt que sur des généralités.
Un nouvel employé s’améliore avec le temps car il apprend progressivement le contexte spécifique à votre organisation. Il apprend qu’une élimination intra-groupe particulière nécessite un traitement spécial, qu’un centre de coûts spécifique suit une affectation non-standard, ou que le dossier de reporting du groupe comporte une nuance concernant la conversion des devises pour une filiale récemment acquise.
Lorsque nos agents ont besoin d’informations supplémentaires pour accomplir une tâche, ils vous posent des questions, par exemple « quand commence votre période de reporting ? ». Ils demandent également si vous souhaitez qu’ils « se souviennent » d’un fait ou d’une information spécifique pour une utilisation future. Et où sont stockées ces informations ? Dans la plateforme de données, aux côté du reste de vos données. Au fil du temps, vos connaissances institutionnelles s’accumulent. Plus votre équipe travaille avec nos agents, plus ces agents deviennent compétents en matière de spécificités de votre entreprise. Ils sont conçus pour cela.
Mes données sont-elles en sécurité ?
La cybersécurité est une discipline qui évolue rapidement, et l’arrivée des LLM a encore accéléré cette évolution. La CFO Solution Platform a été conçue en tenant compte de cette réalité, avec plusieurs couches de protection, des capacités modernes de détection et de réponse, et un niveau de sécurité surveillé en continu.
La CFO Solution Platform est déployée dans cinq régions géographiques, chacune entièrement isolée. Lorsqu’un nouveau client arrive, il choisit dans quelle région géographique ses données seront hébergées. Chaque région est divisée en ce que nous appelons des “tenant pools” : des groupes de clients entièrement isolés les uns des autres. Au sein d’un pool de tenants, chaque client individuel est fortement isolé, ce qui lui interdit d’accéder aux données d’un autre. Les données sont chiffrées en transit et au repos. C’est ce que nous appelons notre modèle d’isolation renforcée. Atteindre ce niveau d’isolation a exigé un investissement considérable dans l’infrastructure de notre plateforme principale, et nous sommes convaincus qu’il s’agit de l’un des investissements les plus stratégiques que nous ayons réalisés.
La plateforme de données hérite de ce modèle d’isolation renforcée. Vos données brutes, vos données nettoyées, votre couche or, votre graphe de connaissances et la mémoire de l’agent se trouvent toutes à l’intérieur de votre tenant, chiffrées, isolées et protégées.
Quelques caractéristiques de la plateforme de données qui méritent d’être soulignées :
- Autorisation par défaut : un agent ne pourra voir que les données auxquelles son utilisateur est autorisé à accéder. Les utilisateurs ne peuvent pas utiliser les agents pour élever leur propre niveau d’accès. Les droits d’accès basés sur les rôles, issus de votre fournisseur d’identité existant, se propagent à travers la Data Platform jusqu’à la couche sémantique.
- Minimisation des données à la frontière du LLM : lorsqu’un agent utilise un LLM pour raisonner, nous ne lui transmettons que les données absolument nécessaires. Nous utilisons des LLM hébergés dans la même région que votre tenant, et, conformément à nos accords d’entreprise avec les fournisseurs de modèles, les requêtes et les réponses ne sont ni conservées ni utilisées pour entraîner les modèles.
Afin de rester rigoureux et de nous assurer de ne rien laisser de côté, nous investissons en continu pour obtenir les certifications les plus pertinentes et répondre aux plus hauts standards de conformité. Ces normes incluent SOC 1, SOC 2, ISO 27001, ISO 27017 et ISO 27018. Nous travaillons également à l’obtention de la certification ISO 42001 (la norme internationale pour les systèmes de gestion de l’IA) et de la BSI C5 (la référence du gouvernement allemand pour la sécurité du cloud), qui devraient nous être accordées d’ici l’été 2026. Au-delà des certifications, nous nous alignons activement sur la loi européenne sur l’IA, la NIS2 et sur la prochaine loi sur la cyberrésilience. Et pour nos clients opérant dans des environnements réglementés par la DORA, notre plateforme est conçue pour soutenir leurs exigences de résilience opérationnelle. La sécurité est l’un des aspects déterminants dans la manière de construire notre plateforme de données.
Envie de voir la CFO Solution Platform de Lucanet en action ?
Participez à notre webinaire pour découvrir en exclusivité la nouvelle génération d’agents de flux de travail qui sera intégrée à la CFO Solution Platform.
Inscrivez-vous dès maintenant