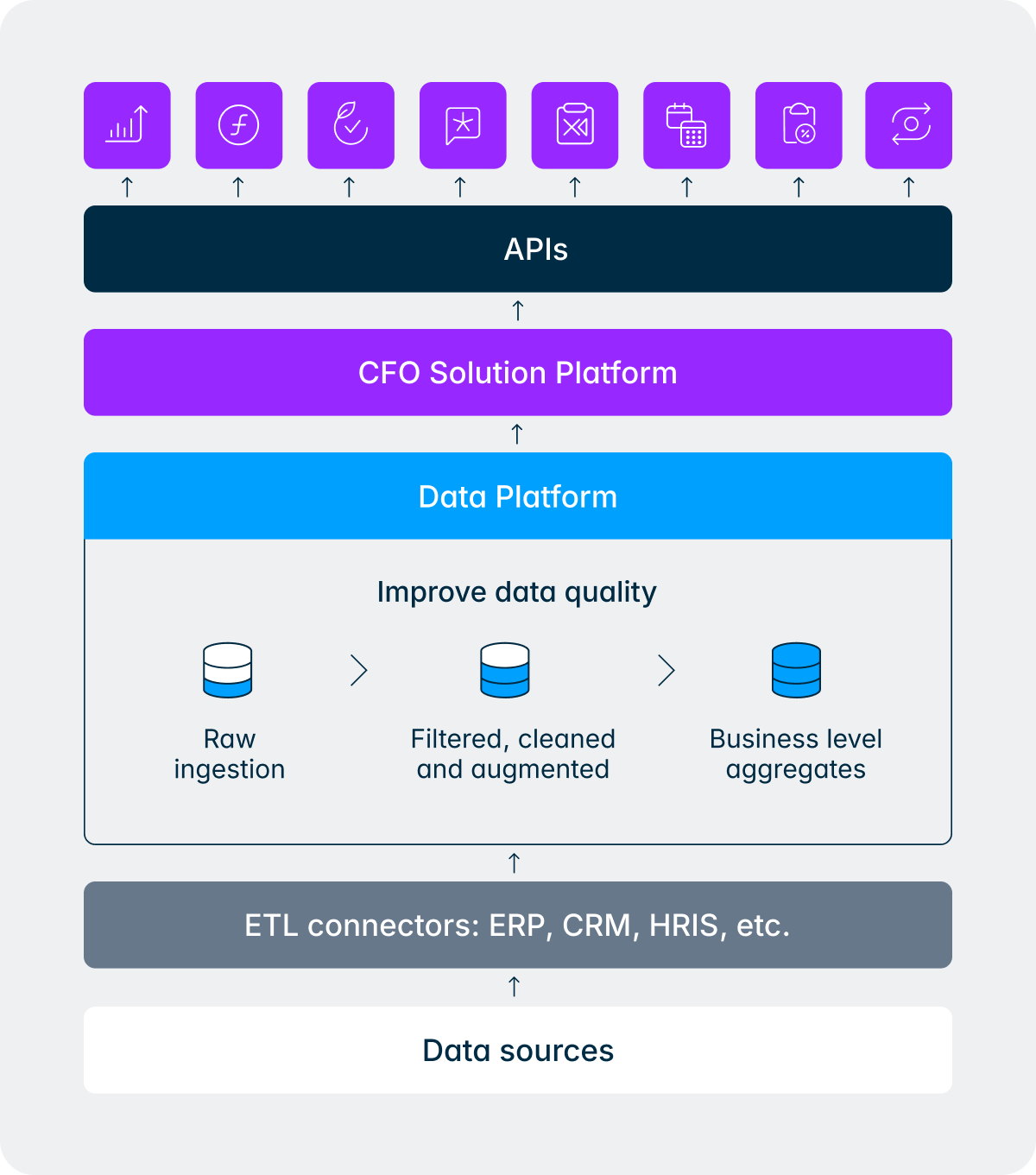
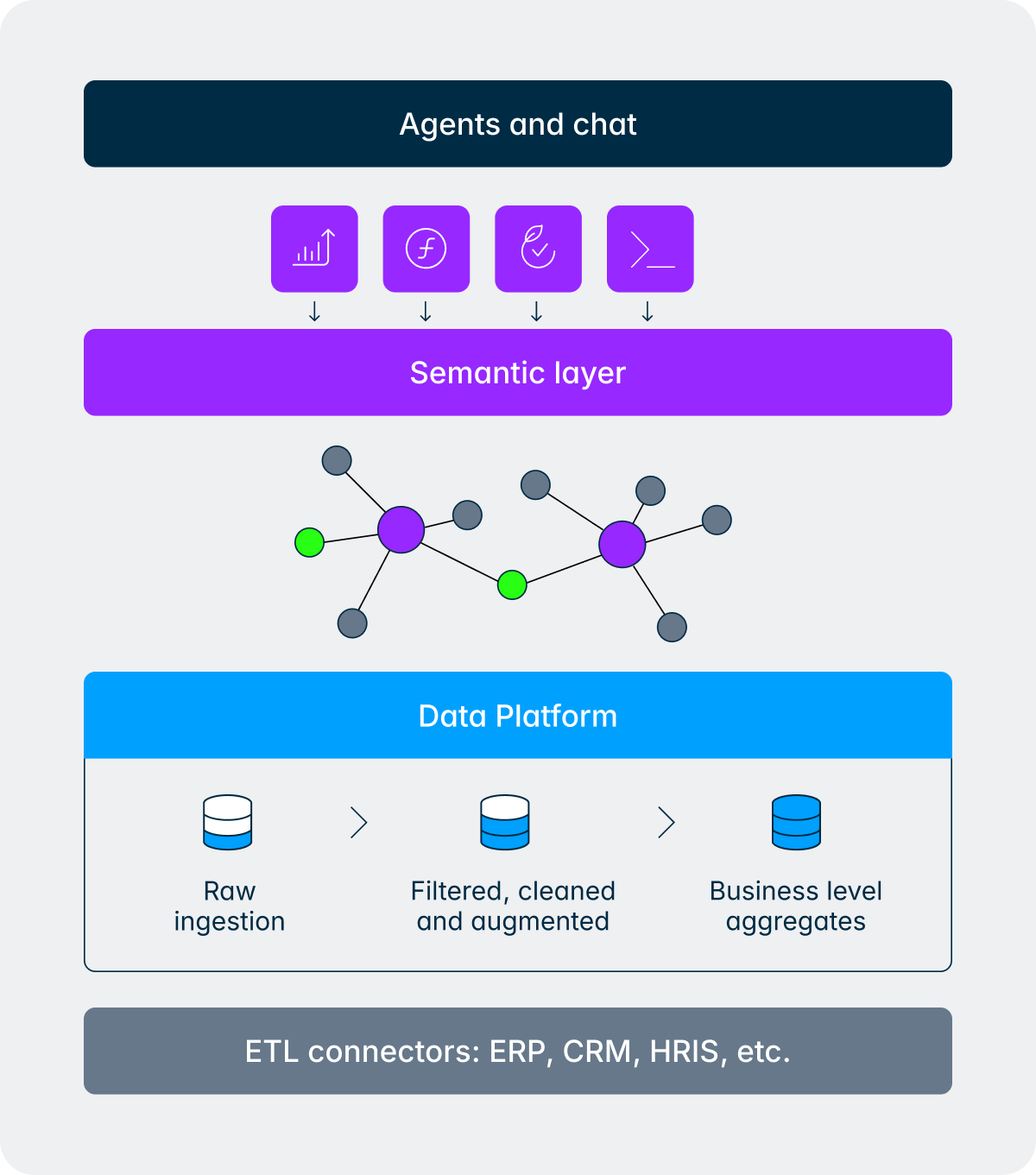
Ecco una domanda che un direttore finanziario potrebbe porre la sera prima di una riunione del consiglio di amministrazione:
"Come è cresciuto il nostro fatturato nel Regno Unito lo scorso anno rispetto alla Germania, e qual è la situazione in termini di numero di addetti alle vendite e di nuovi clienti in queste regioni?"
Quella singola domanda riguarda i dati contabili (fatturato), i dati operativi (dati dei clienti dal CRM), le informazioni sul numero di dipendenti (dall'HRIS), due entità, un confronto rispetto all'anno precedente e una visione regionale. Ecco come l'agente e il livello semantico lo gestiscono insieme:
- L'utente pone la domanda in linguaggio naturale.
- L'agente ragiona su ciò che gli viene chiesto: quali concetti finanziari, quali concetti operativi, quali dimensioni, quale periodo di tempo.
- L'agente invia una o più richieste di dati al livello semantico.
- Il livello semantico esplora il Knowledge Graph per identificare le tabelle, le unioni e le dimensioni rilevanti tra i dati finanziari, HR e operativi.
- La risoluzione delle dimensioni traduce i termini aziendali in identificatori specifici (entità legali del Regno Unito e della Germania, anno fiscale corretto, conti di fatturato, categoria di personale, definizione delle metriche del cliente).
- Il livello semantico recupera i dati, esegue le query rispetto al livello oro e restituisce risultati strutturati.
- L'agente utilizza questi risultati per rispondere alla domanda, con un grafico e una narrazione, mentre l'Intelligence Core cattura la traccia in modo che l'utente possa vedere esattamente come è stata prodotta la risposta.
Processi che prima impegnavano il partner finanziario per mezza giornata (tra ticket BI e successiva riconciliazione) ora si risolvono in pochi secondi. L'agente non sta indovinando. Sta ponendo al data warehouse le domande giuste, nel linguaggio della tua azienda.
Intelligenza a livello di dottorato, ma primo giorno di lavoro
Esiste un modello mentale utile per pensare agli agenti basati su un LLM: immagina di aver appena assunto qualcuno con un'intelligenza a livello di dottorato, straordinarie capacità di ragionamento e profonda conoscenza in una vasta gamma di domini, ma è il suo primo giorno di lavoro. Non sa nulla della tua struttura specifica di consolidato, del tuo piano dei conti, dei tuoi accordi intecompany, delle tue scadenze di reporting o delle decine di piccole convenzioni che i tuoi team finanziari e fiscali hanno costruito negli anni. L'intelligenza grezza è necessaria, ma da sola non è affatto sufficiente.
L'Intelligence Core e la Data Platform sono progettati per colmare questa lacuna. Quando un agente opera all'interno della piattaforma, non si basa esclusivamente sulle conoscenze generali incorporate nell'LLM. Al contrario, l'Intelligence Core fornisce all'agente un accesso strutturato al contesto di cui ha bisogno: le regole del consolidato, la struttura del gruppo, la logica di mappatura, i dati storici e i metadati che descrivono come è configurato l'ambiente specifico. L'agente ragiona con l'intera capacità del modello sottostante, ma ragiona sui tuoi dati, basandosi sulla tua realtà piuttosto che su un contesto generale.
Un nuovo assunto migliora nel tempo perché accumula contesto specifico per la tua organizzazione. Apprende che una particolare eliminazione intercompany richiede un trattamento speciale, che un centro di costo specifico segue un’allocazione non standard, o che il pacchetto di reporting di gruppo presenta una sfumatura riguardo alla conversione valutaria per una filiale recentemente acquisita.
Quando i nostri agenti hanno bisogno di ulteriori informazioni per completare un’attività, porranno domande come "Quando inizia il periodo di reporting?". Chiedono inoltre se desideri che "ricordino" un fatto o un’informazione specifica per un uso futuro. E dove vengono archiviate tali informazioni? La Data Platform, che si affianca al resto dei tuoi dati. Nel tempo, la tua conoscenza istituzionale si consolida. Più il tuo team collabora con i nostri agenti, più questi ultimi acquisiscono competenze sulle specificità della tua azienda. E questo non è un caso, ma il risultato di una progettazione mirata.
I miei dati sono sicuri?
La cybersecurity è una disciplina in rapida evoluzione, e l'arrivo di LLM capaci l'ha resa ancora più veloce. La CFO Solution Platform è stata progettata tenendo conto di questa realtà, con molteplici livelli di difesa, rilevamento e risposta moderni e un livello di sicurezza monitorato costantemente.
La CFO Solution Platform è distribuita in cinque regioni geografiche, ciascuna completamente isolata. Quando un nuovo cliente si registra, sceglie dove risiede il suo tenant, geograficamente. Ogni regione è suddivisa in quelli che noi chiamiamo pool di tenant: gruppi di clienti (tenant) isolati gli uni dagli altri. All'interno di un pool, ogni singolo tenant è rigorosamente isolato, impedendo qualsiasi accesso o visualizzazione dei dati tra ambienti diversi. I dati sono crittografati durante il transito e a destinazione. Lo chiamiamo il nostro modello di rigoroso isolamento. Il raggiungimento di questo livello di separazione ha richiesto un investimento sproporzionato nell'infrastruttura della nostra piattaforma principale, e riteniamo che sia uno degli investimenti più importanti che abbiamo fatto.
La Data Platform eredita questo modello di rigoroso isolamento. I tuoi dati grezzi, i dati ripuliti, il tuo livello oro, il tuo Knowledge Graph e la memoria dell'agente si trovano tutti all'interno del tuo tenant, criptati, isolati e protetti.
Un paio di punti sulla Data Platform che vale la pena sottolineare:
- Autorizzato di default: un agente potrà vedere solo i dati che il suo utente è autorizzato a vedere. Gli utenti non possono utilizzare gli agenti per elevare i propri privilegi di accesso. La gestione degli accessi basata sui ruoli del tuo provider di identità esistente verrà propagata alla Data Platform e al livello semantico.
- Minimizzazione dei dati al confine dell'LLM: quando un agente utilizza un LLM per ragionare, passiamo solo i dati assolutamente necessari. Utilizziamo LLM in hosting nella stessa regione del tuo tenant e, in base ai nostri accordi aziendali con i fornitori di modelli, le richieste e le risposte non vengono né conservate né utilizzate per l'addestramento del modello.
Per rimanere onesti e assicurarci di non aver tralasciato nulla, investiamo tempo ed energie anche per ottenere le certificazioni più rilevanti e rispettare gli standard di compliance più elevati. Questi includono SOC 1, SOC 2, ISO 27001, ISO 27017 e ISO 27018. Inoltre, stiamo lavorando per completare l'ISO 42001 (lo standard internazionale per i sistemi di gestione AI) e il BSI C5 (il benchmark del governo tedesco per la sicurezza cloud), che prevediamo di raggiungere entro l'estate 2026. Oltre alle certificazioni, ci stiamo attivamente allineando al Regolamento UE sull’IA, al NIS2 e al prossimo Cyber Resilience Act. Per i nostri clienti che operano in ambienti regolamentati dal DORA, la nostra piattaforma è progettata per supportarne i requisiti di resilienza operativa. La sicurezza è una delle decisioni portanti nella costruzione della Data Platform.
Vuoi vedere l'Intelligent CFO Solution Platform di Lucanet in azione?
Partecipa al nostro webinar per scoprire in anteprima esclusiva i nuovi agenti di workflow in arrivo sulla CFO Solution Platform.
Registrati ora