Neem bijvoorbeeld een vraag die een CFO de avond voor een bestuursvergadering zou kunnen stellen:
"Hoe is onze omzet in het VK vorig jaar gegroeid in vergelijking met Duitsland en hoe ziet het aantal verkoopmedewerkers en nieuwe klanten eruit in die regio's?"
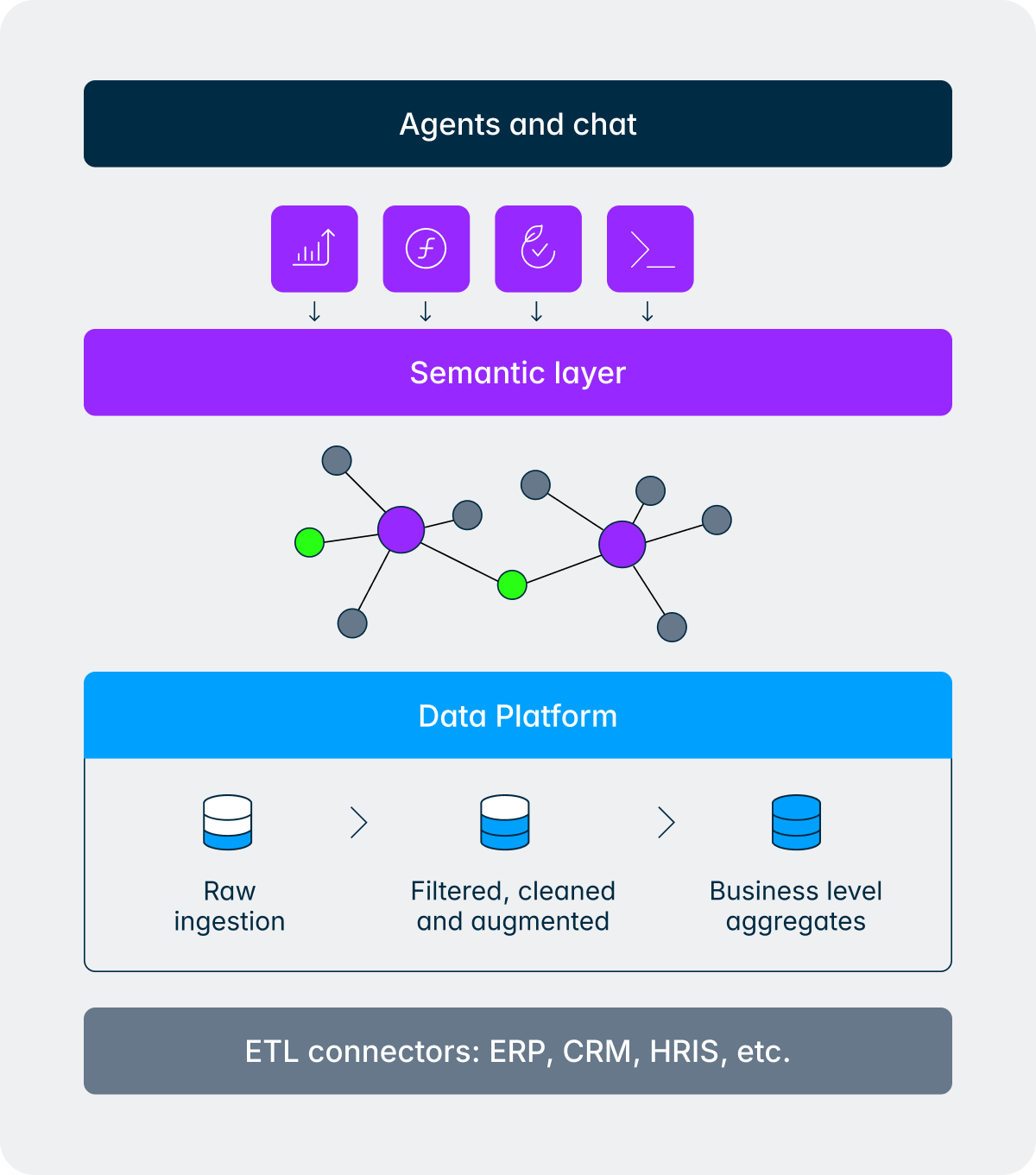
Die ene vraag betreft boekhoudkundige gegevens (omzet), operationele gegevens (klantgegevens uit de CRM), personeelsinformatie (van de HRIS), twee entiteiten, een jaar-op-jaarvergelijking en een regionaal overzicht. Hier is hoe de agent en de semantische laag dit samen afhandelen:
- De gebruiker stelt de vraag in natuurlijke taal.
- De agent redeneert over wat er wordt gevraagd: welke financiële concepten, welke operationele concepten, welke dimensies, welke tijdsperiode.
- De agent stuurt één of meer dataverzoeken naar de semantische laag.
- De semantische laag doorkruist de kennisgrafiek om de relevante tabellen, koppelingen en dimensies van de financiële, HR en operationele gegevenssets te identificeren.
- dimensieresolutie vertaalt zakelijke termen naar specifieke identificatoren (Britse en Duitse rechtspersonen, correct boekjaar, omzetrekeningen, personeelscategorie, definitie van klantstatistieken).
- De semantische laag haalt de gegevens op, voert de queries uit tegen de gouden laag en stuurt gestructureerde resultaten terug.
- De agent gebruikt die resultaten om de vraag te beantwoorden, met een grafiek en een verhaal, en de Intelligence Core legt het spoor vast zodat de gebruiker precies kan zien hoe het antwoord tot stand is gekomen.
Wat een financiële businesspartner voorheen een halve dag kostte, met een BI-ticket en een aansluitende afstemming, kost nu seconden. De agent gokt niet. Het stelt je datawarehouse de juiste vragen, in je eigen bedrijfstaal.
Intelligentie op PhD-niveau, maar direct inzetbaar vanaf dag één.
Er is een nuttig mentaal model om na te denken over LLM-agenten: stel je voor dat je net iemand hebt aangenomen met een intelligentie op PhD-niveau, een buitengewoon redeneervermogen en diepgaande kennis over een opmerkelijk breed scala aan domeinen, maar het is zijn eerste werkdag. Ze weten niets over je specifieke consolidatiestructuur, je rekeningschema, je overeenkomsten tussen bedrijven, je rapportagedeadlines of de tientallen kleine conventies die je financiële en fiscale teams in de loop der jaren hebben opgebouwd. Ruwe intelligentie is noodzakelijk, maar op zichzelf is die lang niet voldoende.
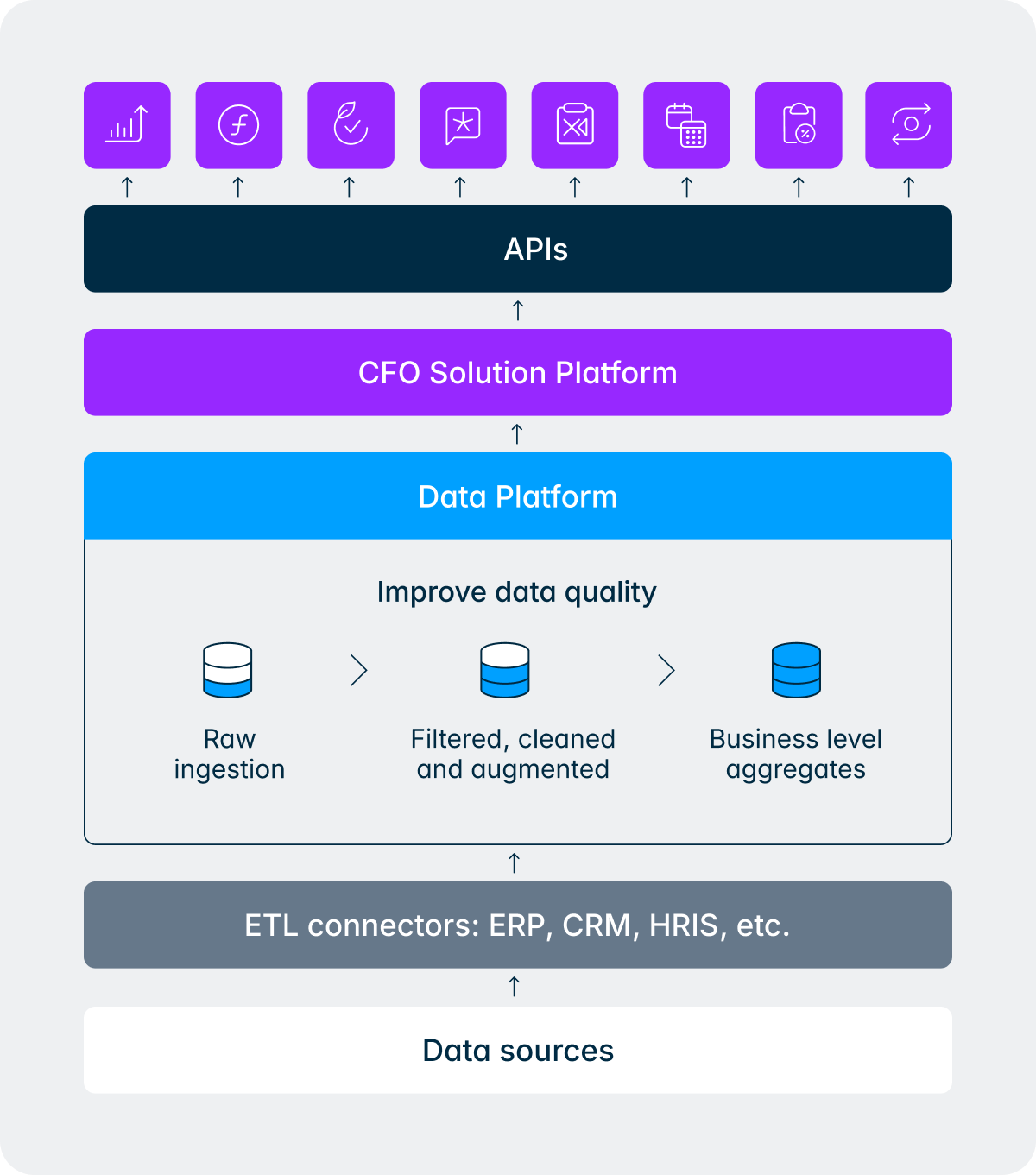
De Intelligence Core en het Data Platform zijn ontworpen om deze kloof te dichten. Wanneer een agent binnen het platform werkt, vertrouwt deze niet alleen op de algemene kennis die in de LLM is ingebouwd. In plaats daarvan biedt de Intelligence Core de agent gestructureerde toegang tot de context die deze nodig heeft: je consolidatieregels, je groepsstructuur, je toewijzingslogica, je historische gegevens en de metagegevens die beschrijven hoe je specifieke omgeving is geconfigureerd. De agent redeneert met de volledige capaciteit van het onderliggende model, maar deze redeneert over je gegevens, gebaseerd op jouw realiteit in plaats van op algemeenheden.
Een nieuwe medewerker wordt na verloop van tijd beter omdat die context verzamelt die specifiek is voor jouw organisatie. Ze leren dat een bepaalde intercompanyeliminatie een speciale behandeling vereist, dat een specifieke kostenplaats een niet-standaard toewijzing volgt, of dat het rapportagepakket van de groep een nuance kent rond valutaomrekening voor een recent overgenomen dochteronderneming.
Als onze agenten aanvullende informatie nodig hebben om een taak te voltooien, zullen ze je vragen stellen, zoals "wanneer begint je rapportageperiode." Ze vragen ook of je wilt dat ze een specifiek feit of informatie 'onthouden' voor toekomstig gebruik. En waar wordt die informatie opgeslagen? Het dataplatform, dat naast de rest van je gegevens staat. Je institutionele kennis wordt in de loop der tijd opgebouwd. Hoe meer je team met onze agenten werkt, hoe bekwamer die agenten worden in de specifieke aspecten van je bedrijf. Dat is de bedoeling.
Zijn mijn gegevens veilig?
Cyberbeveiliging is een vakgebied dat zich snel ontwikkelt, en door de komst van bekwame LLM's gaat het nog sneller. Het CFO Solution Platform is ontwikkeld met die realiteit in gedachten, met meerdere verdedigingslagen, moderne detectie- en responsmogelijkheden en een beveiligingsstatus die continu wordt gemonitord.
Het CFO Solution Platform wordt uitgerold in vijf geografische regio's, elk volledig geïsoleerd. Wanneer een nieuwe klant zich aanmeldt, kiest deze de geografische locatie van de tenant. Elke regio is verdeeld in wat wij tenantpools noemen: groepen klanten (tenants) die van elkaar geïsoleerd zijn. Binnen een tenantpool is elke individuele tenant sterk geïsoleerd van elke andere tenant, waardoor het voor een tenant onmogelijk is om de gegevens van een andere tenant te zien. Gegevens worden zowel tijdens de overdracht als in rust versleuteld. We noemen dit ons sterke isolatiemodel. Het bereiken van dit niveau van scheiding vereiste een onevenredige investering in de infrastructuur van ons kernplatform en we geloven dat het een van de belangrijkste investeringen is die we hebben gedaan.
Het dataplatform erft dit sterke isolatiemodel. Je ruwe data, je gezuiverde data, je goudlaag, je kennisgrafiek en het agentgeheugen zitten allemaal in je tenant, versleuteld, geïsoleerd en beschermd.
Een paar Data Platform-punten die het vermelden waard zijn:
- Standaard met toestemming: een agent kan alleen de gegevens zien die de gebruiker mag zien. Gebruikers kunnen geen agenten gebruiken om hun eigen toegangsniveau te verhogen. Rolgebaseerde toegang van je bestaande identiteitsprovider loopt via het Data Platform en de semantische laag.
- Dataminimalisatie bij de LLM-grens: Wanneer een agent een LLM gebruikt om te redeneren, geven we alleen de gegevens door die absoluut nodig zijn. We gebruiken LLM's die in dezelfde regio worden gehost als je tenant, en volgens onze bedrijfsovereenkomsten met modelproviders worden prompts en reacties niet bewaard of gebruikt voor modeltraining.
Om onszelf eerlijk te houden en ervoor te zorgen dat we niets over het hoofd hebben gezien, investeren we ook tijd en moeite in het behalen van de meest relevante certificeringen en het voldoen aan de hoogste compliance normen. Deze omvatten SOC 1, SOC 2, ISO 27001, ISO 27017 en ISO 27018. We werken ook aan het voltooien van ISO 42001 (de internationale standaard voor AI-managementsystemen) en BSI C5 (de benchmark van de Duitse overheid voor cloudbeveiliging), waarvan we beide verwachten te behalen tegen de zomer van 2026. Naast certificeringen zijn we actief bezig met het afstemmen op de EU AI Act, NIS2 en de aankomende Cyber Resilience Act. En voor onze klanten die actief zijn in DORA-beheerdeomgevingen is ons platform ontworpen om te voldoen aan hun operationele weerbaarheidseisen. Beveiliging is een van de dragende beslissingen in hoe het dataplatform is gebouwd.
Wil je het intelligente CFO Solution Platform van Lucanet in actie zien?
Meld je aan voor ons webinar voor een exclusieve preview van de volgende generatie workflow-agents op het CFO Solution Platform.
Meld je nu aan